Weaknesses in Data and/or Model
Data and machine learning applications are described as garbage in, garbage out. If we put bad data into the model, then the model's performance is virtually guaranteed to have various weaknesses. This is why the early versions (the latest ones as well, but to a much lesser extent) of large language models frequently gave ridiculous or factually incorrect responses.
Weaknesses in the data could come from many sources such as wrong labels or data collection methods. For any supervised learning task where humans label the data by hand, the labelers might make mistakes or inject their personal biases into the labels intentionally or unintentionally.
Weaknesses in the model could come underfitting/overfitting or perhaps the training data was not shuffled properly before training. Some groups may be underrepresented in the training dataset and models tend to pick up on that.
So we would like to know when our models make mistakes and what type of mistakes do they make. One test that we can employ is to take the trained model, pass the training data through it along with the loss function and sort the training examples by maximum loss.
This would allow us to take a closer look at specific data points to see if there is something wrong with the data samples. Are the labels correct or is the example an anomaly, perhaps there are features that are huge outliers. If there are clear issues with the data, then fixing those problems and retraining the model on higher quality data would surely be an improvement.
For our example, we sort the list below for examples with the largest model losses.
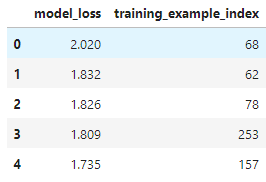
Let's have a look at example with index 68, the one the model had the most trouble with.

We are predicting "G3" which is the final exam score of 10 and above passing and anything below failing. We see that the student's previous two exams "G1" and "G2" were 8 and 9 respectively. Meaning that the student was very close to passing both exams but actually just failed. Since these features are important, the model had difficulty classifying this example.