Data Slice Tests
Most commonly the data that we have does not have an equal amount of samples across various groups features. For example, in an e-commerce dataset, there cannot be an equal number of shoppers across all nationalities, all racial groups, all age groups, etc.
These types of imbalances naturally exist in most real world data. We commonly see significant disparity, especially across protected classes.
Let's take a hypothetical example. Let's assume we have data from a global user base and our model has 99% accuracy. That might seem great, but perhaps there is some nationality that has relatively fewer users on the platform and for this minority group, the model's performance is only 70%. The model goes into production, the minority group users have a poor experience and start leaving. The business starts to suffer while the model's performance gets even better!
This is exactly the kind of situation we want to avoid. So when we assess the performance of our model, we want to ensure that the model does not perform poorly on certain subsets of the data. We need to slice our data on features that may be important to the use case and assess the model's performance on those slices.
For our example, we will slice the data by gender and see if the model's performance on different groups gets better or worse. First, we consider only the female subset of the data and compare the model's performance against the baseline which is measured over the entire dataset.
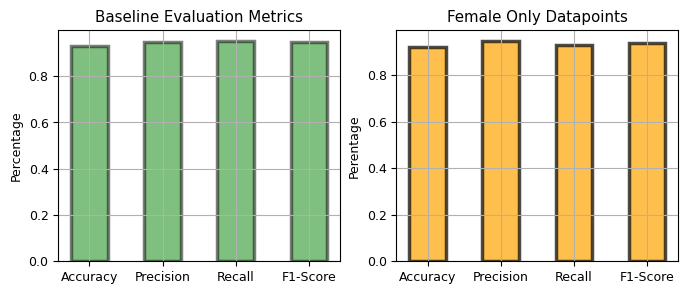
We see that precision increases while recall drops. Let's try again but this time we take only the males subset.

On the males only subset, the precision only slightly goes down while recall goes to almost 100%, and the f-1 score increases as well . Is the model fair? Is the model trustworthy? Is the model high performant? We may want investigate further.