Kubeflow Pipeline & MLOps on GCP
- Dockerizing Data Science Workflow
- Building an ML Pipeline with Kubeflow
- Automated Trigger for Pipeline Runs
If we want to take our data science workflow to a production grade level, we must build machine learning pipelines that run the various tasks of a usual data science workflow.
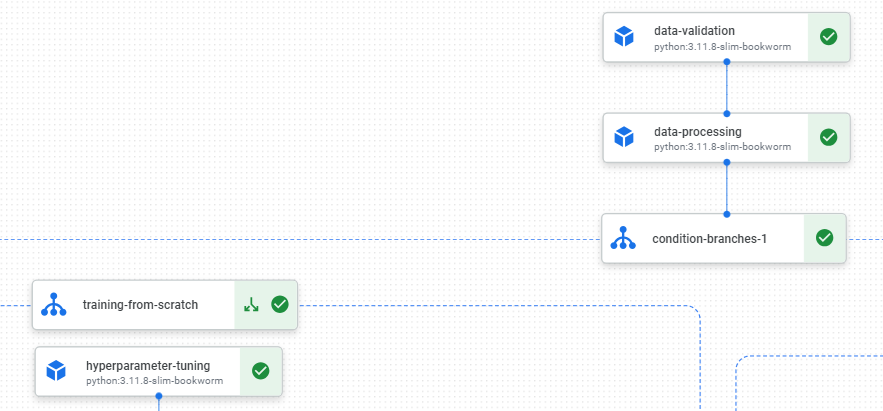
We will begin by writing and testing our Python scripts for tasks such as data validation, data processing, hyperparameter tuning, model training, model fine tuning, etc., and package those scripts into Docker images. We will then push those images to a container registry, in this Google Artifact Registry (GAR).
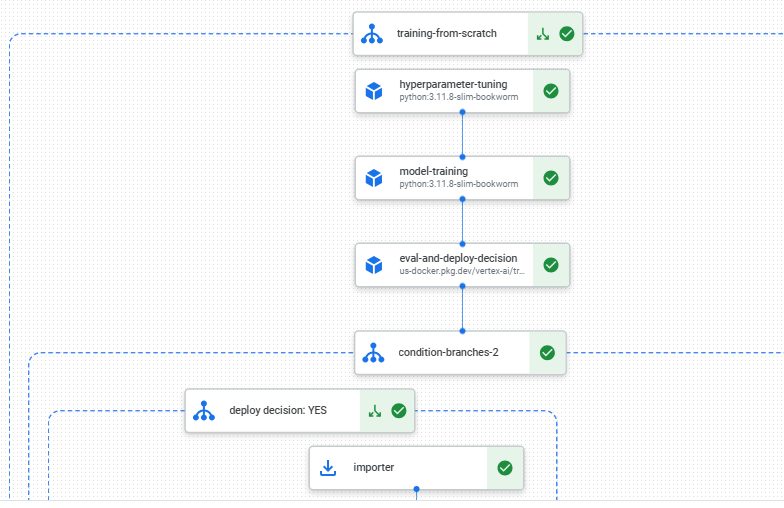
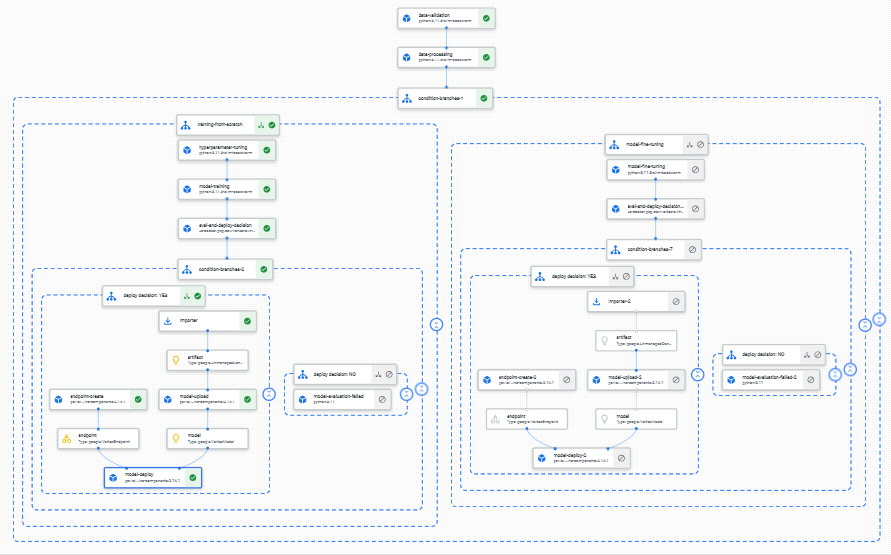
We will then build a Kubeflow pipeline whose DAG (directed acyclic graph) components are the various tasks in our data science workflow. This will also allow us to control the compute we need for each task. For example, we can use lightweight machines for data validation and processing, and GPUs for training.
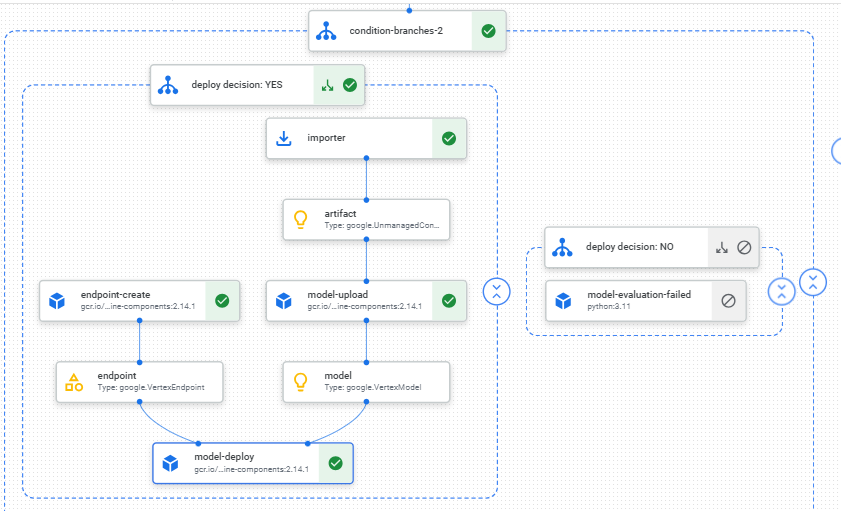
Once the pipeline is built, we can set up a Google Cloud Functions trigger to retrain and fine tune the model on newly collected data. The Cloud Functions trigger will automatically trigger a rerun of the pipeline but a different part of the pipeline will run, for example without hyperparameter tuning or model training from scratch.